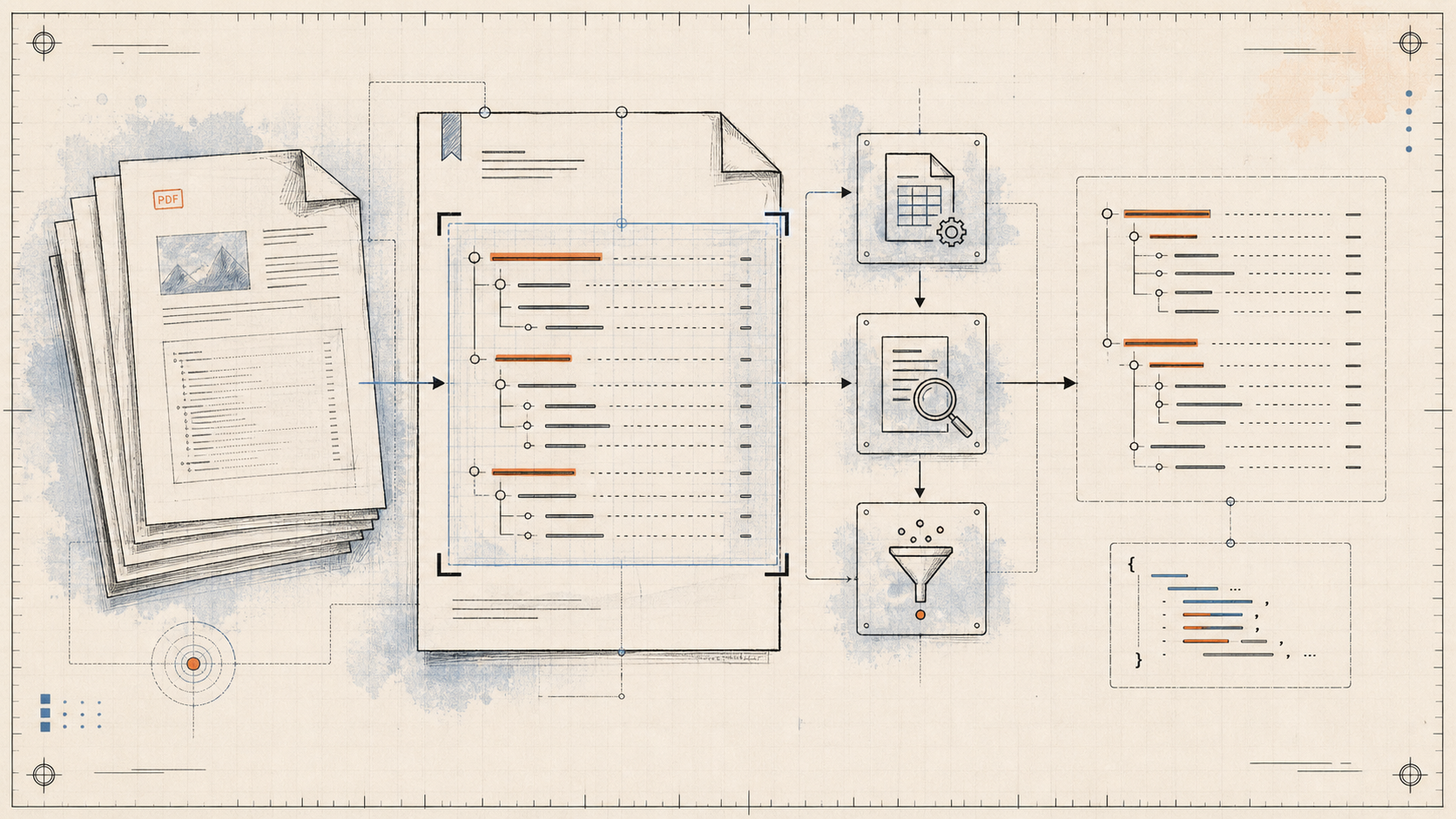
How can you extract a Table of Contents from any PDF — even messy non-standard ones — without ML, DL, or LLMs? Just Python, PyMuPDF, PDFPlumber, and a stack of regex filters.